
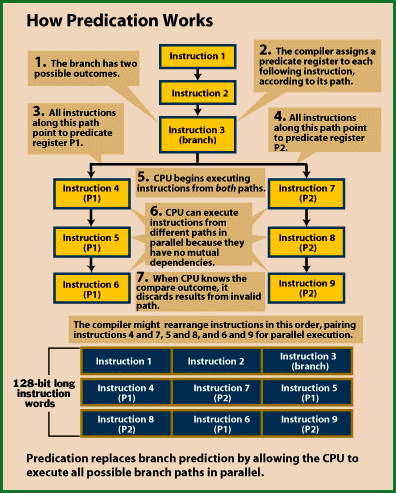
With the introduction of predication Intel have also introduced 64 new predicate registers named P0.... P63 all one bit wide. If an instruction is a branch it assigns a predicate register to all the instructions that follow. Using compare the registers are set and because instructions are executed in parallel one path will be totally discarded at no cost as another one ifs followed by only executing the instructions with predicate register set to 1. This reduces the miss predict penalties and boosts performance since on average every sixth instruction is a branch.
[BACK]
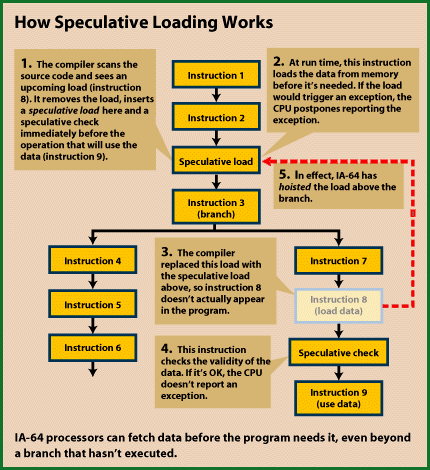
This executes a load from memory before it is actually required thus several instructions can execute straight afterwards because they will not use this data. Right before this data is needed a check has to be made that the right data has been loaded and can now be used. In general the compiler first uses speculative loading to optimise code and then uses predication to optimise code further. To optimise this further. The result is on average that half the required clock cycles are reduced and 2/3 of potential miss predicts through normal branch prediction methods are eliminated. As you can see this will improve the performance greatly.
[BACK]
